Caractères non latins, кирилица et emoji
Présentation
Le traitement des caractères dit "spéciaux" sur Internet concerne différentes spécialités :
- les développeurs pour le stockage, la recherche, l'indexation, les tris
- les infographistes pour le rendu des caractères
- les créateurs de contenus pour le SEO
Nos accents, cédilles et autre trémas sont des "caractères spéciaux" pour les anglophones ; les ф ش 유 यू sont des caractères spéciaux pour les français mais les emoji sont des caractères très spéciaux pour tout le monde :)
Chaque alphabets voit donc les caractères des autres alphabets comme "spéciaux".
Le but est de supporter le maximum d'alphabets (Cyrillique, Coréen, Hindi, etc.) et autres jeux de caractères comme les smiley afin d'éviter :
- l'affichage de caractères non décodés : comme les entités html é ou de l'utf-8 %D0 ou bien des smiley 🙂 ou non supporté comme l'utf-8 é
- des soucis de tri et de recherche
- une mauvaise performance SEO
- des pertes de données
Et permettre la création ou la refonte d'un site non latin ou bien un site multilingue.
1. Développeurs
Il leur faut contrôler que l'ensemble des briques utilisées pour le développement et le rendu du site supportent l'UTF-8 :
- la base de données
- tous les moteurs récents de MySQL supportent l'UTF-8. Seul le choix de l'interclassement sera à effectuer, optez pour UTF8 general CI permettant le tri et la recherche adoc
- en revanche il se pourra que les données actuellement en base soient encodées, il faudra alors les décoder pour être nativement UTF-8
- le moteur de recherche doit envoyer à la base de données les caractères attendus (encodés ou non)
- le format des fichiers
- l'ensemble des fichiers utilisés pour le rendu du site : html, css, php, xml (pour le RSS par exemple) devront être en UTF-8, vérifiez-les avec un bon éditeur de texte
- comme pour la base de données, sauvegarder des fichiers ASCII en UTF-8 ne modifiera pas d'éventuels caractères encodés dans leur contenus, il faudra les convertir à l'aide de scripts
- les informations renvoyées au navigateur
- les headers renvoyés par PHP
- les métadonnées html comme le charset et les informations de langue
- les logs, les fichiers de sauvegardes et le système de restauration
- tous ces systèmes annexes au site doivent supporter l'UTF-8
Cas des URL et des noms de fichiers
Beaucoup d'outils web génèrent automatiquement les URL des pages en se basant sur le titre du document ; mais que font ils des caractères spéciaux ? Très souvent la règle : alphanumériques ainsi que quelques caractères comme le tiret est appliqué. Le nommage des fichier uploadés respectent souvent la même règle.
Comme vu dans la 1ère partie, les accents sont (trop) facilement remplacés par leurs caractères non accentués, pareil pour les trémas et autres cédilles, cela reste lisible. Mais que faire d'un titre composé uniquement de caractères cyrillique ?
Voici quelques solutions, de la plus simple techniquement mais peu satisfaisante, à la plus intéressante mais complexe :
- laisser les rédacteurs traduire et saisir l'URL en latin
- générer un timestamp pour construire l'URL
- créer une table de conversion depuis tous les alphabets vers le latin (ou utiliser une API)
- supporter nativement des URL dans leur alphabet originaux
Cas des Emoji
Les emoji sont un cas plus complexe encore que les alphabets, utilisant un nombre d'octets plus important pour les coder. L'UTF-16 est nécessaire pour supporter un coeur ou un smiley.
Présentation de 2 cas :
Twitter remplace l'emoji par une image, mais conserve le caractère original dans l'attribut ALT de la balise html : tweet de musiquedepub
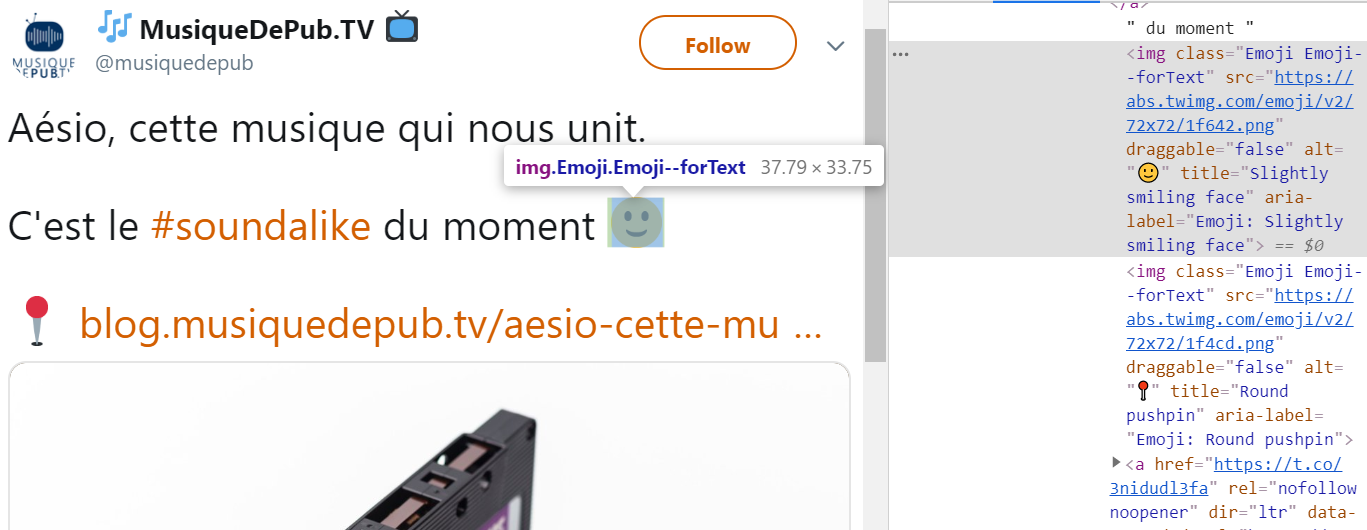
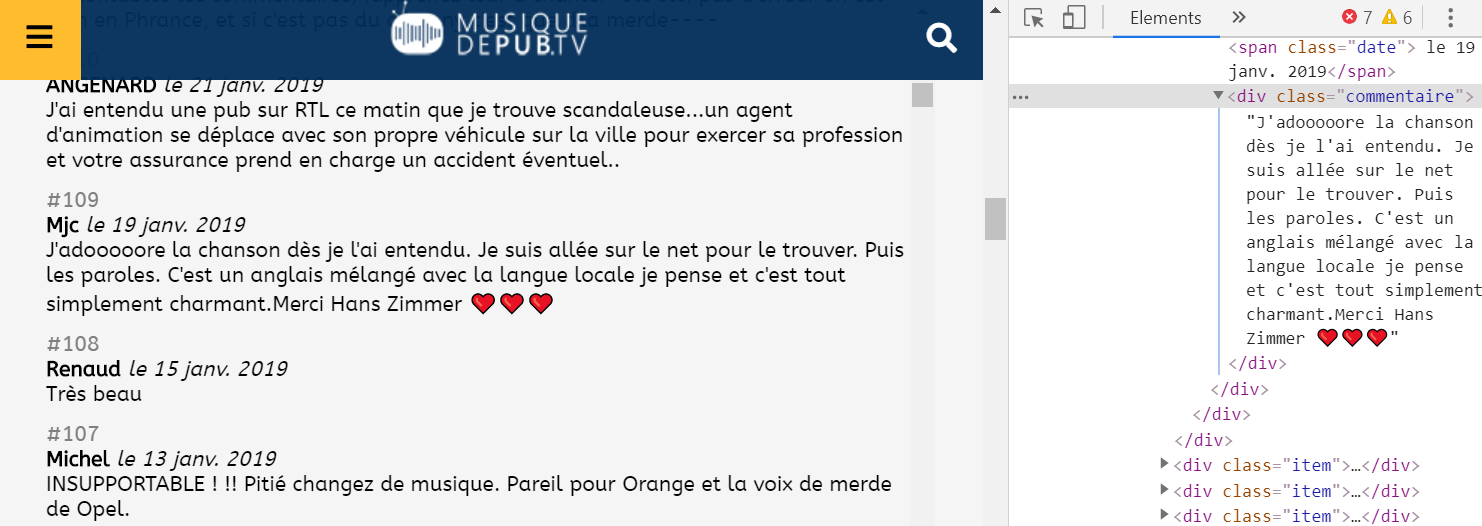
Sur musiquedepub.tv j'ai programmé le système de commentaires pour que les emoji soient stockés de façon encodés, puis décodés pour l'affichage : comme ici le coeur <3
Cela permet de conserver une base de données au format UTF-8 pour ne pas passer à un format plus consommateur en espace comme UTF-16. Mais le système de recherche ne permet pas d'effectuer une recherche sur ce type de caractères.
Cas des noms de domaines
Si beaucoup d'alphabets sont supportés dans les noms de domaines, une étude précise devra être menée quant à la gestion des emails et du référencement.
2. Infographistes
Les polices de caractères doivent supporter les alphabets que les gestionnaires de contenus vont utiliser et les internautes vont insérer via les commentaires.
Les caractères non présent dans la police seront traités par une fonte de backup, dont l'apparence diffère de la police du site.
Exemple ici avec sur 68000.fr où les caractères cyrilliques ne sont pas présent dans la police elephant utilisée pour les titres h1

3. Créateurs de contenus
Une fois les contenus renseignés, la question de leurs performances se pose :
- indexation de toutes les pages par les moteurs de recherche et autres annuaires et plateformes ecommerces
- identification de la langue de chaque page / URL (via l'utilisation de métadonnées)
- apparence des contenus dans le site et dans les moteurs de recherche
- proposer un système de traduction automatique
Suivi des performances de référencement
Voici la query Google permettant de la rechercher dans son indexe : site:68000.fr адрес-на-кирилица
La page est indexée, ses caractères cyrilliques sont supportés dans le l'URL, titre et l'extrait.

Résumé traduit en bulgare
когато уебсайтът е отворен за коментари от интернет потребители по целия свят, кодът на сайта трябва да поддържа всички азбуки или по-добре да вземе под внимание UTF8
След като базата данни, файловият формат и метаданните на сайта са направени съвместими, басовите данни трябва да бъдат преобразувани.
Въпроси за изпълнение:
- качество на индексирането на търсачките?
- правят ли автоматичен превод?
- трябва ли да разделяме съдържание от различни езици?
- какво SEO изпълнение?